
Afinal, o que é Data Science?
- 27 de nov de 2017
Hoje em dia muito se fala sobre Big Data, Machine Learning e Data Science. Esses termos, pronunciados cada vez mais no meio corporativo, algumas vezes são utilizados sem uma compreensão exata do seu significado.
Utilizando o Google Trends, se pode verificar que tanto no Brasil quanto no mundo, nunca houve tanto interesse pelo termo Data Science quanto agora. No ano de 2017, até a data da publicação desse artigo, o interesse cresceu aproximadamente 33% no mundo e mais de 200% no Brasil.
Data Science no mundo
Data Science no Brasil
Os números representam o interesse de pesquisa relativo ao ponto mais alto no gráfico de uma determinada região em um dado período. Um valor de 100 é o pico de popularidade de um termo. Um valor de 50 significa que o termo teve metade da popularidade. Da mesma forma, uma pontuação de 0 significa que o termo teve menos de 1% da popularidade que o pico.
Mas afinal, o que é Data Science?
Desde a década de 90 do século passado, passamos por uma verdadeira revolução em relação a capacidade de criação e armazenamento de dados. Passamos em poucos anos de um disquete capaz de armazenar 1,4 megabytes de informação para sistemas de armazenamento em nuvem com capacidade de 4500 terabytes (3,6 e+10 megabytes ).
A evolução dos sistemas de informação e dos dispositivos que permitem conexão com a internet contribuiu de maneira significativa para essa explosão na geração de dados. Estima-se que nos últimos dois anos foram gerados mais dados do que em toda história da humanidade até então.

Já pensou em quantos vídeos são assistidos, quantas planilhas criadas, quantas mensagens em redes sociais são postadas, quantos e-mails são enviados, quantas fotos são tiradas, quantas buscas e compras são realizadas a cada minuto na internet?
Será que existe alguma maneira de utilizar tudo isso para gerar conhecimento?
Data Science é a maneira de gerar conhecimento, de fazer ciência a partir dos dados. Daí sua estreita relação com a estatística, área do conhecimento cujos métodos permitem descrever, explorar, inferir e predizer a partir dos dados.
O Processo de Data Science
 Tudo começa com os dados, que são os insumos, a matéria prima que será transformada em conhecimento. Nesse processo de transformação, os dados precisam ser organizados, processados e analisados.
Tudo começa com os dados, que são os insumos, a matéria prima que será transformada em conhecimento. Nesse processo de transformação, os dados precisam ser organizados, processados e analisados.
No livro R for Data Science, os autores definem o fluxograma do processo de Data Science com seis etapas que englobam desde a coleta dos dados até a comunicação dos resultados com os públicos interessados, de maneira automatizada e rápida.
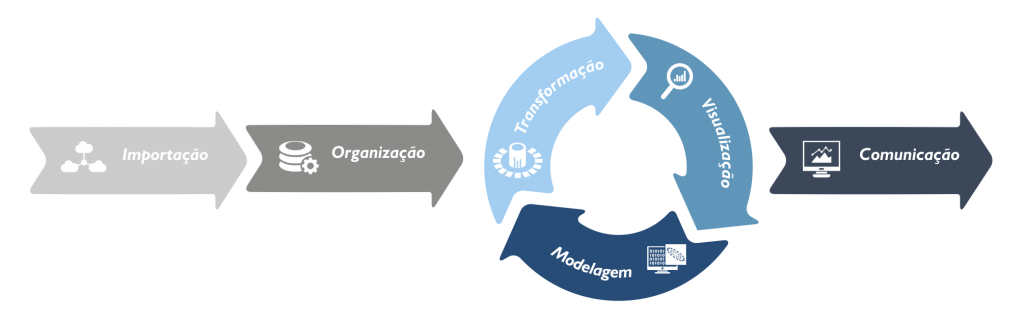
- Importação (Import): Nessa etapa os dados são importados das diversas fontes onde estão armazenados – eles podem estar em arquivos (excel, word, pdf, etc), em bancos de dados (SAP, MySql, MongoDB, etc), na web…
- Organização (Tidy): Esta etapa está relacionada a ações como organizar, arrumar e limpar. É uma importante etapa que se consiste em armazenar a base de dados de forma consistente, por exemplo, com cada coluna representando uma variável e cada linha uma observação.
- Transformação (Transform): Essa transformação pode ser a criação de novas variáveis a partir das variáveis já existentes no banco de dados, através de agrupamentos por exemplo, ou o cálculo de um conjunto de estatísticas descritivas como frequências e médias.
- Visualização (Visualize): É a primeira etapa da geração de conhecimento, em que uma boa visualização dos dados poderá revelar comportamentos inesperados, ou até despertar novos questionamentos sobre os objetivos.
- Modelagem (Model): A etapa de modelagem envolve a utilização de ferramentas que complementam a visualização na geração do conhecimento. É a etapa em que são utilizados modelos estatísticos ou computacionais no processamento dos dados.
- Comunicação (Communicate): O último passo é a comunicação. Não basta todas as etapas anteriores serem executadas com extremo cuidado se não é possível reportar os conhecimentos extraídos dos dados.
Muitos problemas podem ser resolvidos com Data Science
O conhecimento oculto nos dados pode ajudar a resolver muitos problemas nas mais diversas áreas. Independente do ramo do negócio, os dados podem revelar uma realidade que muitas vezes passa despercebida pelos executivos.
Sendo assim, a utilização de Data Science possibilita:
- soluções para os problemas do negócio por meio de técnicas estatísticas e algoritmos complexos;
- otimização e direcionamento de estratégias de negócio;
- entendimento de tendências do cenário econômico, social e mercadológico;
- percepção do sentimento dos consumidores em relação à marca;
- otimização de processos, melhoria da eficiência e maior lucratividade;
- análise preditiva do potencial de vendas, lucros ou prejuízos;
- gerenciamento de riscos;
- aumento da competitividade do negócio e da rentabilidade;
- atenção à oportunidades de negócios;
- etc…
Para exemplificar a aplicação de Data Science em diferentes segmentos, podemos citar:

Indústrias
- Controle e melhoria de processos
- Confiabilidade e tempo de falha
- Previsão da demanda

Setor Financeiro
- Gerenciamento de risco
- Detecção de fraudes
- Redução de custos

Varejo
- Previsão de vendas
- Desdobramento de metas
- Avaliação do comportamento do consumidor
Habilidades necessárias para se tornar um profissional de Data Science
O processo de Data Science é multidisciplinar e requer muitas habilidades dos profissionais que se aventuram na área. Diferentes disciplinas como Estatística, Matemática, Ciência da Computação contribuem para a formação do profissional.
O cientista de dados deve ser um investigador, que busca compreender a realidade através de fatos e dados, fazendo com que as perguntas sejam respondidas com respaldo metodológico aceitável. Para isso precisa conhecer e dominar as diversas ferramentas disponíveis.
Aqueles que anelam se tornar cientistas de dados precisam conhecer e se capacitar no manejo de tecnologias que estão em pleno desenvolvimento. Podemos citar aqui linguagens de programação como R e Python (e seus incríveis pacotes), ferramentas de armazenamento e processamento de dados como Hadoop (MapReduce, Hive and Pig), em estruturas de banco de dados SQL (SQL Server, PostgreSQL, MySQL) e NoSQL (MongoDB, Cassandra), e muito mais.

Quer saber mais sobre Data Science, Big Data e Machine Learning? Tem algum problema para ser resolvido ou alguma pergunta a ser respondida? Entre em contato com nossos consultores e descubra como fazer ciência com os dados. E não deixe de se registrar em nosso blog para acompanhar nossas futuras publicações.
Gostou deste conteúdo?
Informe-se por meio da nossa newsletter!